Introduction
On April 16, the launch of Claude Opus 4.7 sparked complaints on social media, not about new features, but about perceived performance declines. Many developers expressed frustration, feeling that while they were paying the same amount, the service quality had diminished.
Performance Concerns
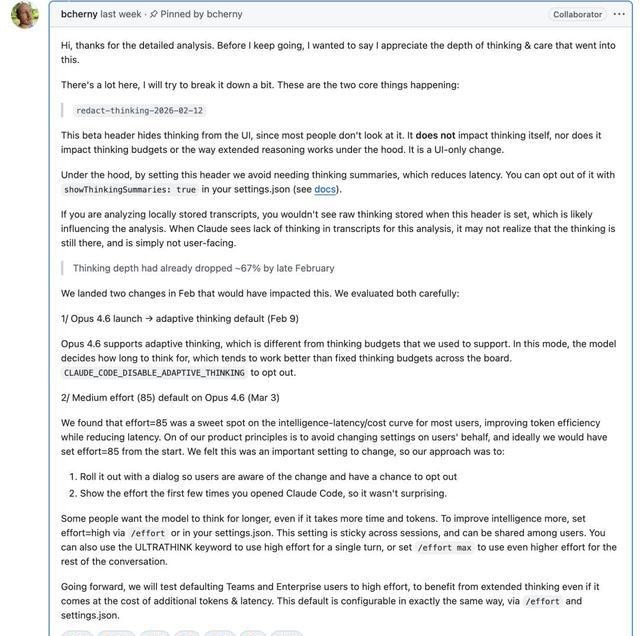
The controversy was notably highlighted by Stella Laurenzo, a senior director at AMD. She analyzed 6,852 conversation files, 17,871 thought blocks, and 234,760 tool calls, concluding that Claude’s performance had shifted significantly since February. The depth of reasoning had decreased, and the stability of complex engineering tasks had also declined.

Data revealed a stark change in the length of thoughts generated by the model, with the median dropping from 2,200 characters to 600 characters, a reduction of nearly two-thirds. The ratio of reading code to hands-on editing also fell from 6.6:1 to 2.0:1, indicating a shift towards quicker fixes rather than deeper analysis.
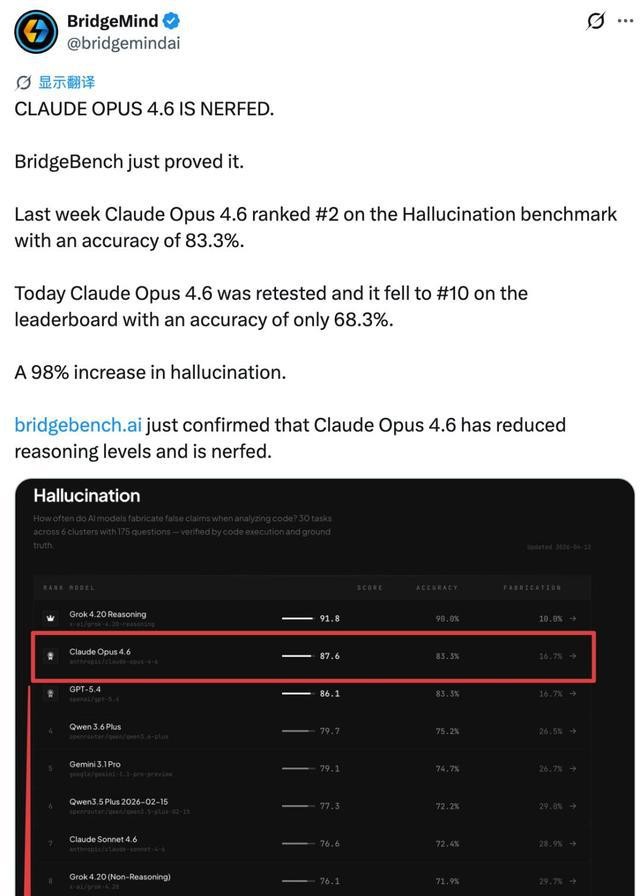
Another concerning statistic showed that the number of premature task terminations rose from 0 to 173, indicating that tasks were frequently left incomplete. Performance on BridgeBench also showed a marked decline, with accuracy dropping from 83.3% to 68.3%, and the model’s ranking fell from second to tenth. Users were particularly troubled by the loss of reliability in complex tasks.
Changes in Default Settings
The controversy extended beyond performance metrics. Anthropic adjusted the default effort level to a medium setting, claiming it was to balance speed and computational costs. However, many users interpreted this as a signal that while the model itself had not degraded, the settings had changed, resulting in faster responses at the expense of depth.
In February, the reasoning process had been obscured, amplifying user frustrations. Those accustomed to monitoring the model’s reasoning found that the screen displayed more blanks, reducing their ability to assess whether the model was functioning effectively. This change in interface not only affected user experience but also altered trust in the AI’s capabilities.
Pricing Model Changes
The pricing model for Claude Enterprise also shifted from a fixed monthly fee to a base rate of $20 plus usage charges. This change had limited impact on light users but posed significant pressure on heavy users. Costs that previously averaged around $200 per month could now potentially triple for some teams.
The explanation behind these changes is straightforward: the cost of reasoning has reportedly tripled over the past year, and computational resources are tight. To maintain profit margins, the platform has shifted the burden onto high-frequency users. While cost control is understandable, a reduction in user experience is harder to accept.
Diverging Opinions
Opinions on the changes have polarized. Heavy programmers and enterprise development teams expressed their frustrations directly, noting that the completion rates for complex code tasks had declined, leading to longer work hours without a corresponding reduction in subscription fees. Conversely, platform advocates argued that the model had not been “dumbed down” but rather that default settings and product strategies had changed.
Following the release of Opus 4.7, Anthropic indicated a focus on restoring performance, enhancing capabilities for complex tasks, and improving tool call efficiency. While there were no immediate pricing changes, the input-output processes remained the same. Quick numerical fixes do not restore trust as swiftly.
New AI Tools
At the same time, new AI design tools were introduced, capable of generating web pages, presentations, landing pages, and product prototypes using natural language. This lowered the barrier to entry, directly impacting the design software market. Following the announcement, stocks for Adobe, Wix, and Figma dropped over 2%, as the capital market reacts quickly to changes in market entry.
Industry Implications
The underlying industry logic revealed by this controversy is significant. While model capabilities are improving, reasoning costs are also rising. Companies are beginning to differentiate between “smarter” and “faster” or “more controllable” AI. Users believe they are purchasing intelligence, but platforms are actually selling computational quotas and usage rules.
This shift is at the heart of the current debate. On the surface, it appears as a decline in intelligence; at a deeper level, it reflects a transition from selling capabilities to selling resource allocations. Users now must consider not only whether tasks can be completed but also if they will be throttled or affected by default settings. Details like the reduction of prompt cache time from one hour to five minutes can significantly impact user experience.
User Reactions
In the comments, supporters of the criticism focused on the concept of disparity. Users who could previously engage in deep reasoning found themselves facing limitations without a corresponding reduction in fees, leading to impatience among long-term users. Some have even altered their usage strategies, opting to use Claude alongside Codex and Gemini for different tasks.
Others took a more measured approach, suggesting that the platform is merely segmenting its products. They argue that heavy tasks should naturally incur higher costs, but the lack of transparency regarding these adjustments has led to a trust crisis, especially after the reasoning process was hidden.
Some developers have shifted their focus to methodology, rejecting single benchmarks as conclusive. They argue that variations in task sets and sample sizes can lead to model ranking discrepancies. Fluctuations on BridgeBench do not capture the full picture; stability in long-term projects and the ability to consistently complete complex tasks are more critical.
Conclusion
This controversy serves as a microcosm of the AI industry reaching a turning point. Vendors are no longer just competing on parameters and demonstrations; they are now contending with cost structures, subscription designs, usage strategies, and default modes. Everyone wants to retain high-frequency customers while avoiding wasteful computational output. The result is that users seek reliability, while platforms often provide controllability.
In summary, Claude has not suddenly lost its capabilities; rather, product strategies, cost pressures, default configurations, and interface presentations have collectively altered user perceptions. Data has provided critics with reasons for their concerns, while the official explanations have offered reassurances. The market has opened up opportunities for new models, but the pressing question remains: “What exactly are users getting for the same amount of money?”
As this situation continues to unfold, it remains to be seen whether Opus 4.7 can restore its reputation, whether the new billing method for the enterprise version will push heavy users to competitors, and how the design tools will further impact traditional software. One thing is certain: AI has not only become more powerful; it has also become more expensive and complex, necessitating clearer understanding.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.